Scaling sphinxsearch
Scaling fulltext search solution sphinxsearch.com and manticoresearch.com setup in high load production
Scaling sphinxsearch
Sphinxsearch is an open-source search server that is in production for more than 10 years, it is stable, efficient and simple to use. I will cover some scaling and setup details that are not so obvious I wanted to share some good practices, they are easy to find but having them all in one place , because some information is hidden deep inside documentation, some on forums and some known only after years of using in production. I would recommend anyone who needs plug&play solution for fulltext/autocomplete search and also tag/recommendation based search to try out sphinx.
Simple setup
Lets start with simple setup and evolve it into scalable configuration.
Initial example Dockerfile for our sphinxsearch is Alpine Linux 3.8
FROM alpine:3.8
STOPSIGNAL SIGTERM
RUN addgroup -g 1111 -S dalek && adduser -u 1111 -S -G dalek dalek
RUN apk add --no-cache sphinx sudo && \
rm -rf /tmp/* && \
rm -rf /var/cache/apk/*
EXPOSE 9312
EXPOSE 9212
ARG config
RUN mkdir -p /var/run/sphinxsearch
COPY COPY/sphinxsearch.conf.tmp /etc/sphinx/sphinx.conf
COPY COPY/docker-entrypoint.sh /docker-entrypoint.sh
RUN chown dalek:dalek /var/run/sphinxsearch
RUN chown dalek:dalek /var/lib/sphinx && rm -rf /var/lib/sphinx/*
RUN echo "dalek ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers
USER dalek
ENTRYPOINT ["/docker-entrypoint.sh"]
CMD ["searchd", "--nodetach"]Already some highlights
- SIGTERM as stopsignal, because it is “searchd” daemon official graceful shutdown signal
- Do not run as root, it is not required, so we use random user id=1111, name=dalek
- We EXPOSE two ports because “searchd” can listen on multiple ports, and later in your app you can load balance using that
- /var/lib/sphinx is data directory and /var/run/sphinxsearch is pid directory, must have correct permissions
- We copy sphinxsearch.conf.tmp as our sphinx config into default location for configuration, usually config is auto-generated from template (i.e. per environment)
Entrypoint
We need to launch searchd daemon without forking/detaching and pass execution flow to that process, use common docker-entrypoint bolerplate to create this initial entrypoint script
- If we found config, we run indexer which tries to create/index all defined indexes in config file
- Also launch cron with sudo, if we want to re-index the indexes later on
#!/bin/sh
set -e
# If the sphinx config exists, try to run the indexer before starting searchd
if [ -f /etc/sphinx/sphinx.conf ]; then
indexer --all > /dev/console
fi
#launch crond daemon in background with disabled logs
#It has to run as root unfortunatelly
#(unless 3rd party cron is used https://github.com/aptible/supercronic)
sudo crond -l 6 -d 6 -b -L /dev/console
#launch sphinx
exec "$@"sphinx.conf
Here is example configuration containing some products index from MySQL source
- In Sphinx integer attributes size can be defined to further optimize space/memory usage
- Use index and source inheritance and autogenerate configs programatically
- sql_query_pre can contain temporary table creation or other preparation for main query (db optimizer settings)
- Indexer memory limit needs to be different per production/test - another reason for autogenerated configs, because the memory is always reserved even if not needed (i.e. index data could be 1mb but whole amount is locked)
- You generally dont want query_log, and do want some increased defaults for max_filter_values and seamless_rotate = 1
- Workers could be threads/fork/prefork, realtime indexes only work with threads, also max max_children only has effect if non threads is selected the actual sources of sphinxsearch is best documentation of how exactly those settings work
- Results are fetched with ranges query to reduce server load (separate queries over books table instead of one big)
# Custom attribute sizes (bytes to unsigled int's, (possible values = `2^(bits)-1`) <--
#1 bits = 2 [can have only 2 values (0 or 1)]
#2 bits = 3
#3 bits = 7
#4 bits = 15
#5 bits = 31
#6 bits = 63
#7 bits = 127
#8 bits = 255
#9 bits = 511
#10 bits = 1023
#Z bits = (2^Z)
# Custom attribute sizes (bytes to unsigled int's, (possible values = `2^(bits)-1`) <--
##
# DATABASE INDEX SOURCE -->
##
source options
{
type = mysql
sql_port = 3306
# MySQL specific client connection flags
# optional, default is 0
# enable compression
mysql_connect_flags = 32
}
##
# DATABASE INDEX SOURCE <--
##
#We extend option source, and inherit type,port and all other options
#all sql_query_pre are inherited if not defined in this source, if at least 1 defined nothing is inherited
source books_localhost_src : options
{
sql_host = books-mydbhost.com
sql_user = mydbuser
sql_pass = mydbpass
sql_db = mydbname
#Every time indexer needs to index, in creates new connection
#This is executed after the connection is established, before sql_query
sql_query_pre = SET NAMES utf8mb4
sql_query_pre = SET SESSION query_cache_type=OFF
sql_query_pre = START TRANSACTION READ ONLY
sql_query_pre = CREATE TEMPORARY TABLE IF NOT EXISTS tmpbooks \
(id int(10) unsigned NOT NULL AUTO_INCREMENT PRIMARY KEY, \
book_id int(10) unsigned NOT NULL) \
ENGINE=MEMORY DEFAULT CHARSET=ascii AS ( \
SELECT books.id \
FROM books) \
sql_query_range = SELECT MIN(id), MAX(id) FROM tmpbooks
sql_range_step = 10000
sql_query = \
SELECT books.id, \
books.author_id, \
books.timestamp_added, \
books.timestamp_changed, \
books.available \
FROM books \
WHERE books.id >= \$start AND books.id <= \$end
sql_attr_uint = author_id
sql_attr_timestamp = timestamp_added
sql_attr_timestamp = timestamp_changed
sql_attr_uint = available:1
sql_attr_multi = uint books_prices from query; SELECT book_id, price_int FROM books_prices WHERE price_int IS NOT NULL
}
index books_localhost_idx
{
source = books_localhost_idx
path = /var/lib/sphinx/books_localhost_idx
docinfo = extern
preopen = 0
# need concrete match, ignore morphology
morphology = none
# memory locking for cached data (.spa and .spi), to prevent swapping
mlock = 0
# index all (words of 1 char len)
min_word_len = 1
type = plain
}
indexer
{
#IMPORTANT while running, indexer will reserve this amount of memory even if its not needed
#So if we run multiple indexers in parallel its easy to run out of memory
mem_limit = 128M
}
searchd
{
listen = 9313:sphinx
listen = 9213:sphinx
log = /dev/null
#query_log = /tmp/sphinx_query.log
read_timeout = 5
pid_file = /var/run/sphinxsearch/searchd.pid
#max_matches = 1000
#@see http://sphinxsearch.com/forum/view.html?id=5099 (invalid attribute set length)
max_filter_values = 8192
seamless_rotate = 1
preopen_indexes = 0
unlink_old = 1
workers = threads # for RT to work
binlog_path = /var/lib/sphinx/
client_timeout = 20
#maximum amount of children to fork (concurrent searches to run)
max_children = 1000
attr_flush_period = 0
mva_updates_pool = 32M
listen_backlog = 10
#Affects distributed local indexes on multi-cpu/multi-core box (recommended 1xCPUs count)
dist_threads = 4
query_log_format = sphinxql
prefork_rotation_throttle = 100
binlog_flush = 0
}Delta setup
Now if you have hundreds of millions of books, and your data changes only insignificantly every day (books are added or removed or made unavailable), then good approach is to have a scheme of main + delta index, where main index is calculated on boot, while delta is calculated every hour/day and just updates main index.
Using this setup requires more advanced knowledge of sphinx configuration options and internals, especially if you serve more than one index and more than one delta index on a single searchd daemon.
I would NOT RECOMMEND SERVING delta index directly and will not give example of that, as the merge tool exists and serving delta is just more overhead to searchd daemon while priority should be maximum performance on main indexes, so less memory and less locks are essential.
Instead indexer merge should be used to merge delta results into main index once ready.
Let’s add delta index for books added/modified last hour.
Delta will fetch only added/modified books for last hour, so we should re-index delta every hour and merge it into main index.
source books_localhost_src_delta_1 : books_localhost_src
{
sql_query_pre = SET NAMES utf8mb4
sql_query_pre = SET SESSION query_cache_type=OFF
sql_query_pre = START TRANSACTION READ ONLY
sql_query_pre = CREATE TEMPORARY TABLE IF NOT EXISTS tmpbooks \
(id int(10) unsigned NOT NULL AUTO_INCREMENT PRIMARY KEY, \
book_id int(10) unsigned NOT NULL) \
ENGINE=MEMORY DEFAULT CHARSET=ascii AS ( \
SELECT books.id \
FROM books \
WHERE timestamp_added > UNIX_TIMESTAMP(DATE_SUB(CURDATE(), INTERVAL 60 MINUTE)) \
OR timestamp_changed > UNIX_TIMESTAMP(DATE_SUB(CURDATE(), INTERVAL 60 MINUTE)) \
) \
}
index books_localhost_src_delta_1 : books_localhost_idx
{
source = books_localhost_src_delta_1
path = /var/lib/sphinx/books_localhost_src_delta_1
#1 - all attributes stay on disk. Daemon loads no files (spa, spm, sps). This is the most memory conserving mode
#We never serve delta index directly, no point in loading to memory
ondisk_attrs = 1
}
And important is to me merge the index into main with index tool, remember not to serve delta indexes with searchd, you can define delta in config but list served indexes as searchd argument on start
/usr/bin/searchd --nodetach --index myindex1 --index myindex2 --index books_localhost_idxThen every hour we recalculate delta, notice NO –rotate flag needed as index is not locked by searchd.
indexer --noprogress --verbose books_localhost_src_delta_1 2>&1 At last we merge the delta into main, using merge-dst-range to eliminate no longer available books.
indexer --rotate \
--noprogress \
--verbose \
--merge books_localhost_idx books_localhost_src_delta_1 \
--merge-dst-range available 1 1 \
2>&1 At this point we have merged changes from last hour into our main index.
IMPORTANT Notes
- Index rotation is done asynchronously, and there is no indication for rotation end, that means if you have >1 delta indexes you want to merge into main be carefull with locks as searchd may crash, to prevent that add small (sleep of 5 seconds or so) delay between executing –rotate with merge on deltas
- Separate your indexes into three groups:
- served indexes (dont serve deltas, dont serve distributed index parts)
- booted indexes (not distributed local index, instead parts it consists of, we dont need delta on boot)
- deltas indexes (lists of [MAIN + DELTA] indexes you want to merge) You can still keep definition of all those indexes in one config.
Following above rules you will be able to create complicated setup i.e.
- Serve multiple distributed local indexeses (books1, books2)
- Each consisting of multiple shards (books1_1, books1_2, books_2_1, books_2_2)
- Each shard having its own delta (books1_1_delta, books1_2_delta, books2_1_delta, books2_2_delta)
Merge/rotate/serve without issues/locks/crashes - preferably autogenerating the whole sphinx.conf.
Update 27.10.2018
- Index rotation is async, and all indexes are attempted to be rotated. We can use this to our advantage, instead of merge+rotate+wait each delta, we can only merge each delta and execute rotate in the end with use of –nohup flag.
#merge all your delta indexes into main indexes (delta1 -> main1, delta2 -> main2, ...)
indexer --rotate \
--nohup \
--noprogress \
--verbose \
--merge books_localhost_idx books_localhost_src_delta_1 \
--merge-dst-range available 1 1 \
2>&1
#send single SIGHUP to searchd, will trigger ALL served indexes check for new/fresh data (basicly .new files)
kill -s SIGHUP `pidof searchd`
Bash tools
Todo
Update 13 Nov 2018
After migrating to SphinxQL from SphinxAPI, there are basicly no performance improvements just because of that. And regarding article ‘Sphinx search performance optimization: attribute-based filters’ from 15.01.2013 on percona website, in my case i was using only numeric attributes for filtering and saw:
- 0% performance change after moving from SphinxAPI to SphinxQL for the same attribute filter queries
- worse performance when mixing attribute search and field-search while putting the same integer MVA attributes into sql_field_string “indexed” attribute
- there are none performance boost when using persistent SphinxQL connections compared to SphinxAPI persistent connections
- there is small boost to using persistent SphinxQL connections vs non-persistent SphinxAPI but the difference is only seen in peak traffic/rps and just require searchd configuration changes (workers=tread_pool, max_children=YOUR_PEAK_ACTIVE_CONNECTIONS)
Additionnal downside is that there is no way to get “total_found” value via SphinxQL in same request - one would need to execute “SHOW META” SQl statement, instead of one SphinxAPI request (that’s two requests vs 1 in SphinxAPI).
Good thing is debugging and profiling SphinxQL is easier and more friendly to operator.
Update Jan Nov 2019
Further stress/load testing was performed with distributed JMeter setup to fine-tune the ManticoreSearch for fast small queries, as degraded performance was identified under peak loads when number of (persistent) connections spikes by 2-5x times.
Jmeter setup was two machines each 4core 8gb ram, one as JMeter distributed server another as ManticoreSearch server, both located in same VPC on same AWS Region and subnet - so the latency is minimal. Tests were done with SQL API using from one to 5 listening ports, concurrently and non concurrently up to 1000 concurrent users per port. Test SQL query filter values were randomized on average response time is 33ms (4ms - 10000ms during JMeter tests)
- workers = thread_pool definetly shows more linear clients/response-time growth than threads, so its better
- setting watchdog=0 didnt impact performance in any way
- searchd listening on >1 socket only degrades performance ~2% and distributing your load per socket doesnt make difference, there seems to be dedicated thread for networking no matter how many listening sockets you define.
- listen_backlog is important directive that is by default very low, increasing it to your net.core.somaxconn (~4096 or so) makes sense, and prevents searchd from dropping connections (as per tcp listen backlog directive), reduced error rates from 2.5% to 0% during tests
- net_workers=1 changing it to anything other than 1 degrated performance, big values >N-cpu affected performance significantly
- net_wait_tm=-1 we changed it to -1 setting poller to 1ms interval, this reduced the response times and makes sense, performance increased
- net_throttle_accept or net_throttle_action didnt make any difference
- max_children value was removed (default to unlimited), this improved the performance and made graph linear
Usefull commands for profiling Manticoresearch:
- show plan;
- show profile;
Final JMeter 3.3 load test profile with 1000 concurrent users (connections), SQL interface, ramp-up = 0, ManticoreSearch 2.7.3 in Docker, c5.xlarge AWS instance (4vCPU, 8GB RAM, 10Gbps network)
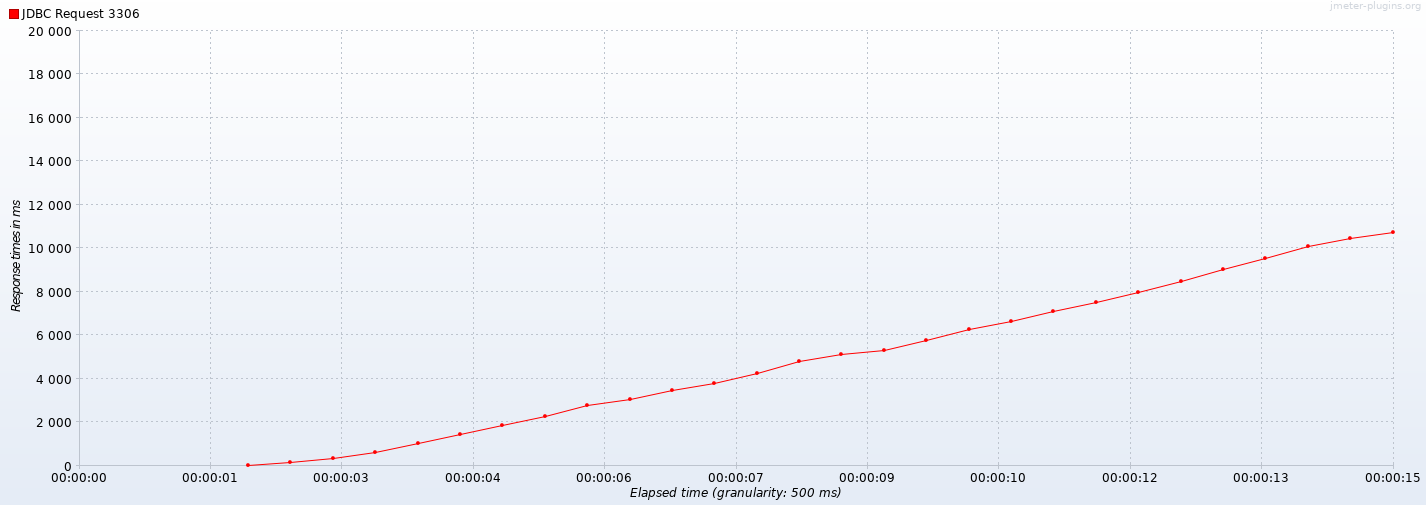
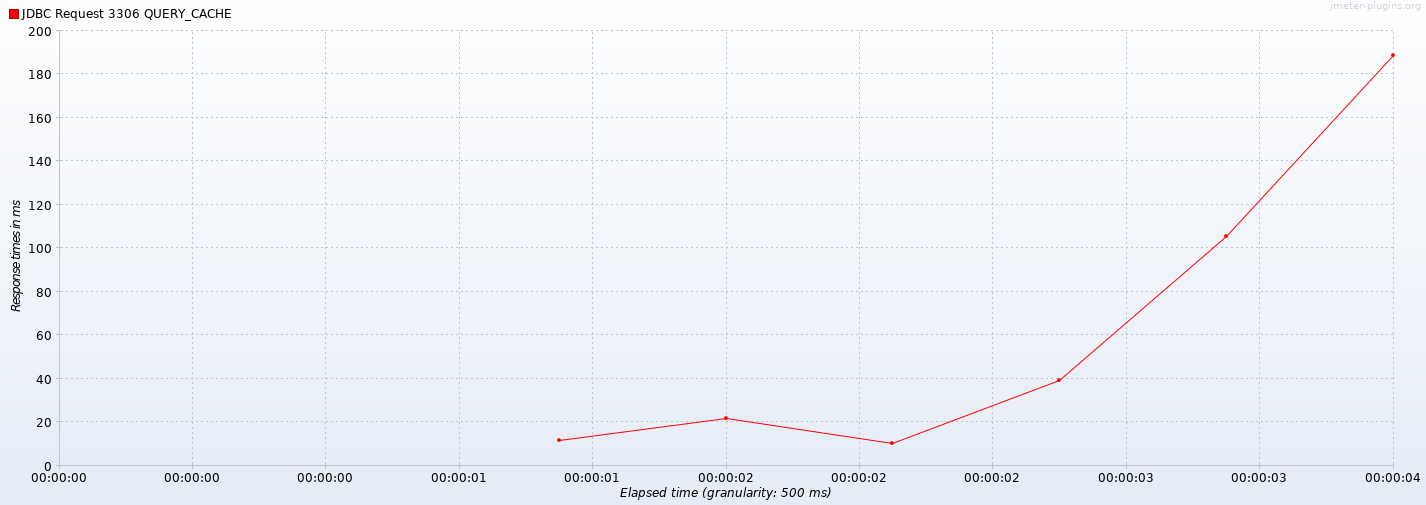
Further approach of using full-text search on attributes improved results by 50x times (5000% better)
- MVA attributes indexed as sql_field_string
- sql_field_string used in MATCH() duplicating sql_attr_* filters usint EXTENDED match syntax
- qcache_thresh_msec = 5 reduced minimum cache hit time
SELECT a,
b,
(IN(c_sql_attr_multi, 1, 2, 3) AND IN(d_sql_attr_multi, 4, 5, 6))) as e
FROM indexa
WHERE e = 1became
SELECT a,
b,
(IN(c_sql_attr_multi, 1, 2, 3) AND IN(d_sql_attr_multi, 4, 5, 6))) as e
FROM indexa
WHERE MATCH('((@c_field 1 | 2 | 3) (@d_field 4 | 5 | 6))')
AND e = 1Final JMeter 3.3 load test profile with 1000 concurrent users (connections), SQL interface, ramp-up = 0, ManticoreSearch 2.7.3 in Docker, c5.xlarge AWS instance (4vCPU, 8GB RAM, 10Gbps network), and MATCH optimization
Links
- Sphinx 2.2.11-release reference manual
- Delta updates
- Local index in distributed declaration
- Handling duplicate document-ids
- Delta indexing example
- Sphinx tricks
- Sphinx index file formats
- Sphinx sources
- Sphinx in docker
- Sphinx index merging
- Sphinx 2.3.x fork Manticoresearch
- Optimization: attribute-based filters
- Refactored SphinxAPI client
https://moar.sshilko.com/2018/10/06/Scaling-sphinxsearch